AWS Skillbuilder : Building with Amazon Aurora Databases (Korean)
Amazon Aurora
Amazon Aurora는 MySQL 및 PostgreSQL과 호환되는 관계형 데이터베이스 엔진으로, 클라우드 환경에 최적화되어 있습니다. Amazon Relational Database Service(RDS)를 통해 데이터베이스 설정, 패치, 백업 등의 관리 작업을 자동화하여 사용자의 관리 부담을 덜어줍니다. Aurora는 최신 저장 시스템을 사용하여 데이터를 저장하며, 모든 데이터는 3개의 AWS 가용 영역에 분산되어 각각 독립적인 2개의 저장 장치에 복제됩니다. Aurora의 데이터베이스 엔진은 빠른 스토리지 활용을 위해 사용자 지정되었습니다.

Amazon Aurora는 다음과 같은 특징을 가지고 있습니다:
- 기본 쿼리 처리: 모든 검색된 데이터를 Aurora 클러스터에서 단독으로 처리.
- 비교 쿼리: 추가 성능 개선을 위해 사용.
- 축소 쿼리: 일부 I/O 및 컴퓨팅 작업을 스토리지로 분산 처리.
- 가변 쿼리: 새로운 데이터가 포함된 테이블에서 빠른 성능을 발휘하며, 분석 워크로드에 적합.
실습시작
1. 활동 환경 탐색
① AWS 콘솔 검색 필드에서 RDS를 입력한 다음 RDS를 선택해 데이터베이스를 클릭합니다.
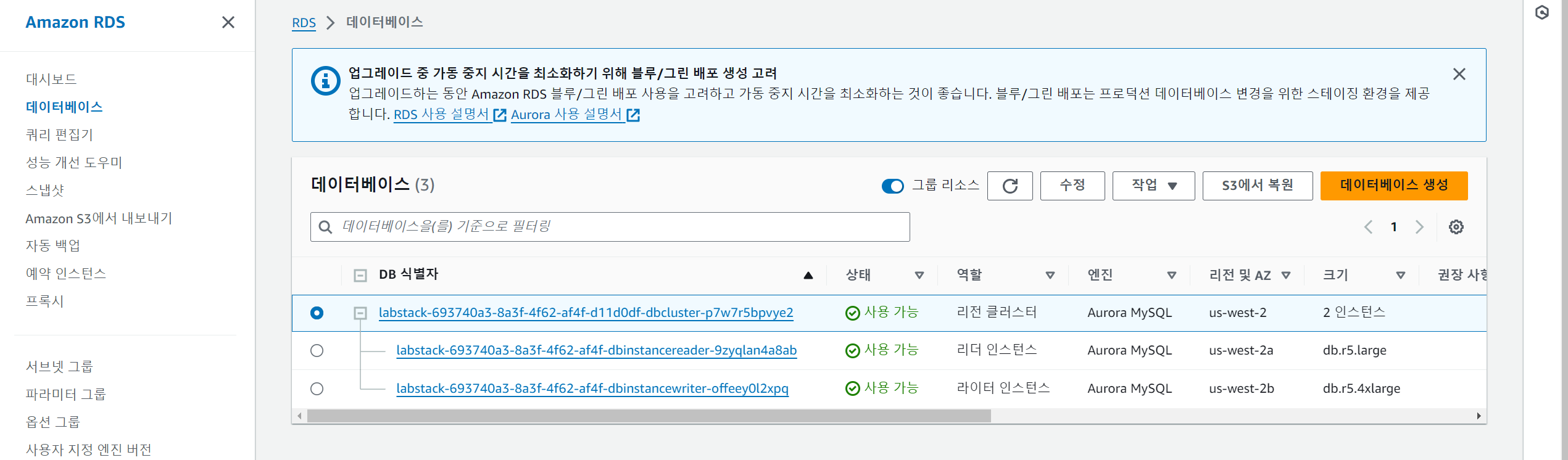
② 리전 클러스터의 식별자를 클릭하여 파라미터 속성에 들어가서 상단의 파라미터 필터 필드에서 aurora_parallel_query를 입력하여 매개 값이 ON 되어 있는 것을 확인하고 aurora_disable_hash_join을 입력하여 매개 값이 0인것을 확인합니다.


2. 데이터 및 병렬 쿼리 설정 탐색
① 활동 페이지의 왼쪽에 CommandHostSessionUrl 값을 복사하여 새 브라우저 탭에 붙여넣기 합니디. CommandHost 터미널 있는 탭 창이 뜨면 코드를 입력합니다. (DBUserName) 및 (SmallDBEndpoint) 은 활동 페이지의 왼쪽에서 확인하실 수 있습니다.
mysql -u (DBUserName) -p -h (SmallDBEndpoint) #my SQL 연결

② ontimeflights 데이터베이스를 사용하고 데이터베이스에 테이블을 표시합니다.
USE ontimeflights #ontimeflights 데이터베이스 사용
SHOW TABLES; #테이블 보여주기
③ 첫 번째 출력은 테이블의 구조를 보여줍니다. CarrierCode 와 CarrierTableName , 2개의 열이 있습니다 . 전투에 항공사 코드 대신 항공사의 이름이 표시되도록 이 테이블을 flightdata 테이블에 조인할 수 있습니다. 두 번째 출력은 이 테이블에 1,928개의 기록이 포함되어 있음을 보여줍니다.
DESCRIBE carriers; #carriers 테이블의 구조
SELECT FORMAT(COUNT(carrierCode), 0) AS 'Number of Carriers' FROM carriers; #carriers 테이블에 있는 carrierCode 열의 총 개수
④ carriers 테이블에서 데이터 샘플을 측정하고 flightdata 테이블에 대한 세부적인 정보를 보여줍니다.
SELECT * FROM carriers LIMIT 10;
DESCRIBE flightdata; #flightdata 테이블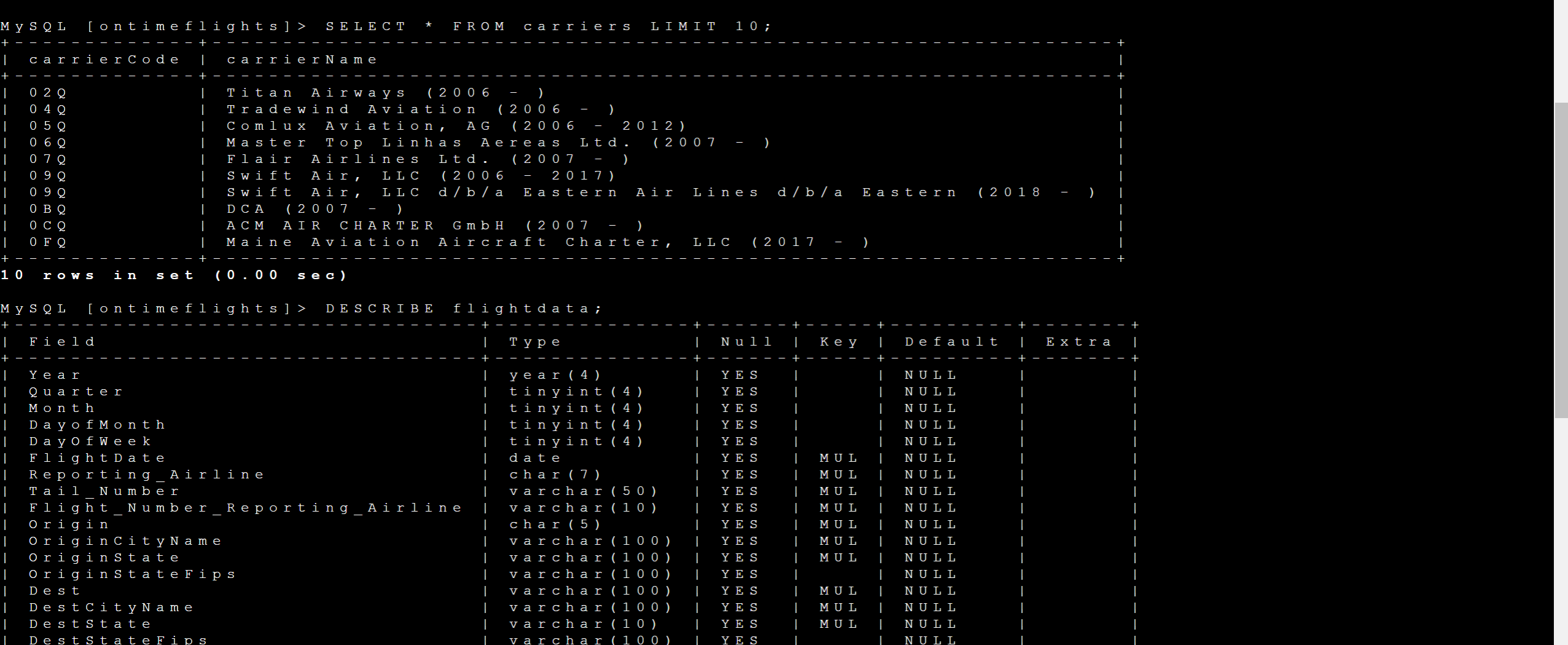
⑤ flightdata 테이블에서 Year 열에 있는 값들의 총 개수를 살펴보겠습니다.
SELECT FORMAT(COUNT(Year), 0) AS 'Number of Flights' FROM flightdata;
- AWS CLI를 사용하여 하위 쿼리 구성
① 쿼리 세션에 대해 선택적으로 사용 여부를 확인합니다. 데이터베이스의 인스턴스의 시스템 변수 값을 조회합니다.
SELECT @@aurora_parallel_query;
SELECT @@aurora_disable_hash_join;
- 병렬 설정 전환
① aurora_parallel_query 시스템 변수를 0으로 설정합니다. 즉, 병렬 쿼리 기능을 비활성화합니다. aurora_parallel_query 시스템 변수를 1로 설정합니다. 즉, 병렬 쿼리 기능을 활성화합니다.
SET SESSION aurora_parallel_query=0; #병렬 쿼리 비활성화
SELECT @@aurora_parallel_query;
SET SESSION aurora_parallel_query = 1; #병렬 쿼리 활성화
SELECT @@aurora_parallel_query;
SELECT @@aurora_pq_force;
- aurora_parallel_query: 1
- aurora_pq_force: 0
- CLOUDWATCH 대시보드 조사
① AWS 콘솔로 있는 탭으로 가서 검색 필드에 CloudWatch를 입력하고 왼쪽 탐색 창에서 대시보드를 클릭합니다,

② ontimeflights-Dashboard 대시보드 이름을 클릭하고 RDS:추가 PQ 분석 그래프를 관찰합니다. 이 그래프에 차트를 사용하여 세 가지 지표의 그래프 및 색상을 기록합니다. 점점 더 쿼리를 찾으려고 노력하고 있기 때문에 모두 기준선 0에 있어야 합니다.

3. 병렬 쿼리의 영향 이해
- 기본적 특성 효과 예측
① CommandHost 터미널 있는 탭으로 돌아가 병렬 쿼리를 확인합니다. EXPLAIN 명령어는 데이터베이스가 주어진 쿼리를 어떻게 실행할 것인지에 대한 실행 계획을 제공합니다. 출력의 Extra 열에 NULL 이어야 합니다.
EXPLAIN
SELECT
Origin, Dest, Reporting_Airline,
AVG(DepDelayMinutes) 'Avg Departure Delay', COUNT(DepDelay) 'Delayed Flights'
FROM flightdata;
EXPLAIN
SELECT
Origin, Dest, Reporting_Airline,
AVG(DepDelayMinutes) 'Avg Departure Delay', COUNT(DepDelay) 'Delayed Flights'
FROM flightdata
WHERE DepDelay > 0
AND Origin NOT IN ('TWF', 'SNA', 'ORD')
② Innodb_buffer_pool 분석합니다.
SHOW GLOBAL STATUS LIKE 'Innodb_buffer_pool%';
③ 병렬 쿼리가 비활성화 일때 데이터 베이스의 효과를 확인합니다.
SET SESSION aurora_parallel_query=0;
SET SESSION aurora_pq_force=0;
SELECT AVG(DepDelayMinutes + ArrDelayMinutes) AS "Average Delay"
FROM flightdata
WHERE Distance > 200
AND OriginCityName NOT IN ('Chicago IL', 'Miami FL');
④ 병렬 쿼리가 활성화 일때 데이터베이스의 효과를 확인합니다.
SET SESSION aurora_parallel_query=1;
SET SESSION aurora_pq_force=1;
SELECT SQL_NO_CACHE AVG(DepDelayMinutes + ArrDelayMinutes) AS "Average Delay"
FROM flightdata
WHERE Distance > 200
AND OriginCityName NOT IN ('Chicago IL', 'Miami FL');
SHOW GLOBAL STATUS LIKE 'Innodb_buffer_pool%';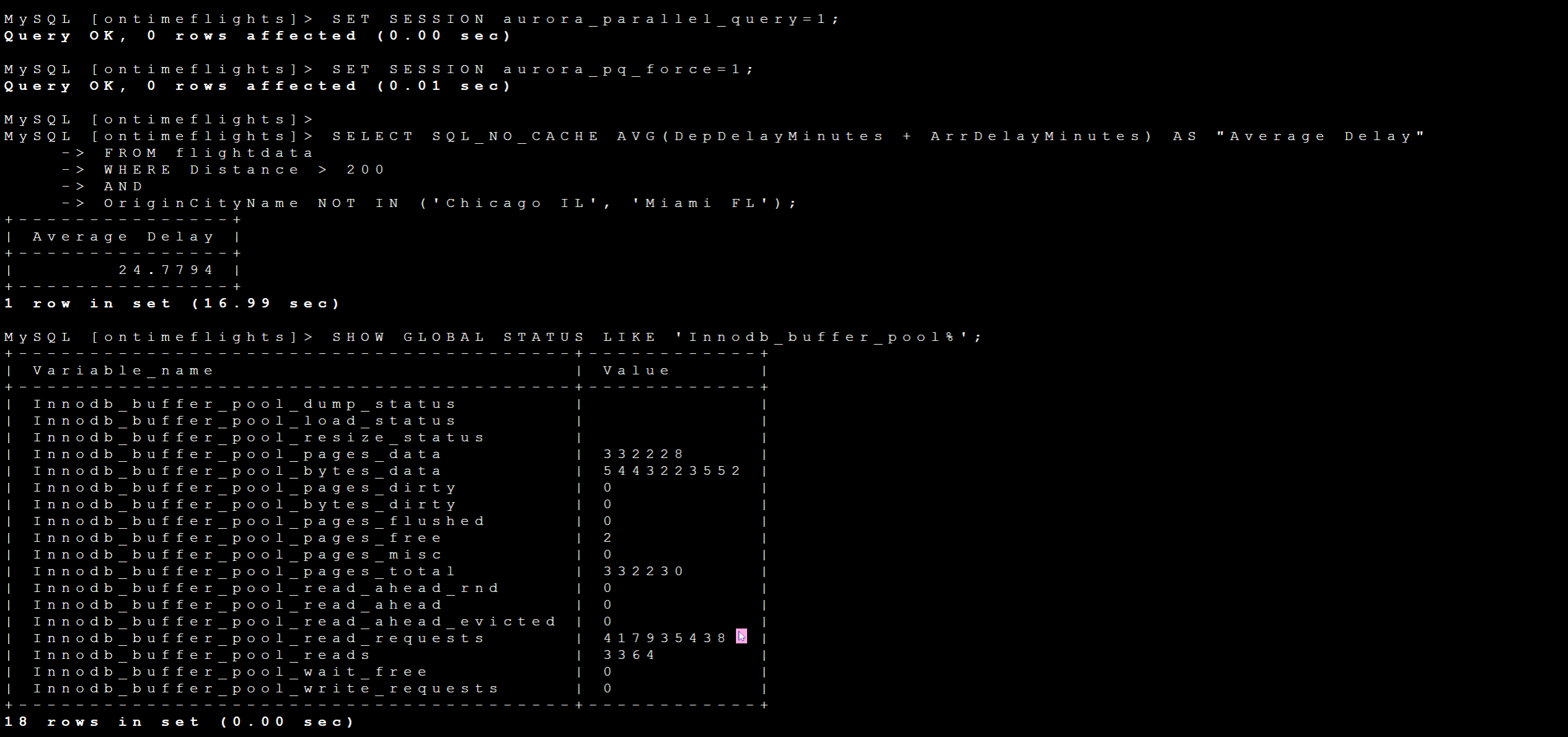
4. 관계없이 비교하는 변수에 영향을 미치는 이해
- AURORA 인스턴스 조사
① AWS 콘솔 검색 필드에 RDS를 입력하고 왼쪽 탐색 창에서 데이터베이스를 클릭합니다. 리더는 크기는 db.r5.large 입니다.

② 리더 인스턴스에 해당하는 데이터베이스를 클릭하여 유일 클래스, vCPU 수, RAM을 확인합니다. 라이터 인스턴스와 비교하면 리더는 더 작은 클래스로 구성되어 있으며, 상대적으로 vCPU 수와 RAM 양이 더 적습니다.


- 더 작은 인스턴스로 테스트
① 인스턴스 유형에 허용되는 최대 동시 병렬 쿼리 세션을 MySQL에 연결된 명령 호스트 세션 창에서 실행합니다. 결과로 인스턴스에서 동시에 실행할 수 있는 최대 병렬 쿼리 세션 수가 1 임을 나타냅니다
SHOW GLOBAL STATUS LIKE 'aurora_pq_max_concurrent_requests';
② 데이터베이스 서버와의 연결을 끊고 시스템 관리자 권한을 EC2-USER로 변경하고 항공사 코드가 AA, UA, DL 또는 b6이고 거리가 1,000마일 미만인 항공편을 가져옵니다. (DB)친 부분은 활동 페이지 왼쪽을 참고해주세요.
exit #현재 데이터베이스 서버와 연결 중단
sudo su - ec2-user && cd ~ #EC2-USER로 변경
./run-pq.sh (DBUserName) (SmallDBEndpoint) (DBUserPasswd) #SMALLDBENDPOINT사용
SET SESSION aurora_parallel_query=1;
SET SESSION aurora_pq_force=1;
SELECT SQL_NO_CACHE
carriers.carrierName AS 'Carrier',
flightdata.Origin AS 'Origin Airport',
flightdata.Dest AS 'Destination Airport',
AVG(flightdata.ArrDelay) AS 'Average Arrival Delay',
COUNT(flightdata.ArrDelay) AS 'Number of Delays',
SUM(flightdata.Cancelled) AS 'Cancelled Flights'
FROM flightdata
JOIN carriers ON (carriers.carrierCode = flightdata.Reporting_Airline)
WHERE flightdata.Distance < 1000
AND flightdata.Reporting_Airline IN ("AA", "UA", "DL", "B6")
GROUP BY Origin, Dest
ORDER BY carriers.carrierName;
- 첫 번째 쿼리는 두 번째 쿼리보다 훨씬 적은 시간을 사용해야 합니다. 이는 이 작은 인스턴스가 한 번에 하나의 병렬 쿼리만 수행할 수 있기 때문입니다.
- 더 큰 인스턴스로 테스트
① 앞에서는 SmallDBEndpoint 했지만 이번에는 LargeDBEndpoint로 해보겠습니다. ()친 부분은 활동 페이지 왼쪽을 참고해주세요.
mysql -u (DBUserName) -p -h (LargeDBEndpoint) #LargeDBEndpoint사용
② ontimeflights 데이터베이스를 사용하고 인스턴스 유형에 허용되는 최대 동시 병렬 쿼리 세션을 MySQL에 연결된 명령 호스트 세션 창에서 실행합니다. 이 인스턴스에서 동시에 실행할 수 있는 최대 병렬 쿼리 세션 수가 8 임을 나타냅니다
USE ontimeflights; #ontimeflights 데이터베이스를 사용
SHOW GLOBAL STATUS LIKE 'aurora_pq_max_concurrent_requests';

③ ontimeflights 데이터베이스 서버와의 연결을 끊고 MySQL 클라이언트를 사용하여 데이터베이스에 접속하고 쿼리를 실행합니다. ()친 부분은 활동 페이지 왼쪽을 참고해주세요.
exit
./run-pq.sh (DBUserName) (LargeDBEndpoint) (DBUserPasswd)
- 더 큰 인스턴스에서 지원되는 더 많은 수의 동시 병렬 쿼리로 인해 두 쿼리 모두 이 기능을 사용할 수 있으므로 더 큰 인스턴스의 두 쿼리 모두 대략 동일한 시간이 경과해야 합니다.
- 두 인스턴스 간의 병렬 쿼리 성능을 비교 분석하기 위해 CLOUDWATCH 대시보드를 조사
① AWS 콘솔이 있는 창의 검색 필드에 CloudWatch를 입력하고 선택한 다음 왼쪽 탐색 창에서 대시보드를 클릭합니다. ontimeflights-Dashboard 대시보드 의 이름을 클릭합니다 .

결과
RDS: Large Instance PQ Stats
인스턴스 클래스에서 지원하는 최대 동시 병렬 쿼리 요청은 8 이고 , 동시에 실행되는 쿼리 2개 에는 각각 2개의 병렬 쿼리 세션이 필요하므로 조절이 관찰되지 않았습니다( Aurora_pq_request_throttled : 0). Aurora 관계형 데이터베이스 내의 새로운 데이터에 대해 정기적으로 실행해야 하는 대규모 분석 문은 병렬 쿼리에 적합할 수 있습니다.
Aurora_pq_request_throttled : 0 (1분 간격 동안 요청하지 못한 병렬 쿼리 세션)
Aurora_pq_request_attempted: 4 (시도된 병렬 쿼리 요청의 총 횟수)
Aurora_pq_request_executed: 4(실제로 실행된 병렬 쿼리 요청의 총 횟수)
느낀점
Amazon Aurora가 성능 및 안정성을 제공하는 클라우드 기반의 데이터베이스인 걸 알았을 때 데이터베이스 시스템에 대해 관심이 있어서 그런지 실습해보고 싶었다는 생각이 들었었다. 근데 배운적도 없고 대충 어떤 건지 이론만 알고 있어 어떻게 다뤄야 하는지를 몰라서 실습을 할 수 없었었다. 하지만 이번에 skiillbuilder 구독을 하면서 좋은 경험을 했던 거 같다. 처음에는 막상 어떻게 해야 하는지 헤매고 있어서 이해하려고 노력을 좀 많이 했던 거 같다. Amazon Aurora가 병렬 쿼리 기능을 제공하여 대량의 데이터를 처리할 때 성능을 향상 시킨다는 것을 깨달았다. 중간에 mysql서버에 코드를 작성하면서 password 적는 부분에 화면에 나타나지지가 않아서 내가 스스로 잘못한 줄 알고 헤맸었다. 그 점이 실습 활동지에 나오지가 않아서 아쉬운 부분이였다.
출처: AWS Skillbuilder